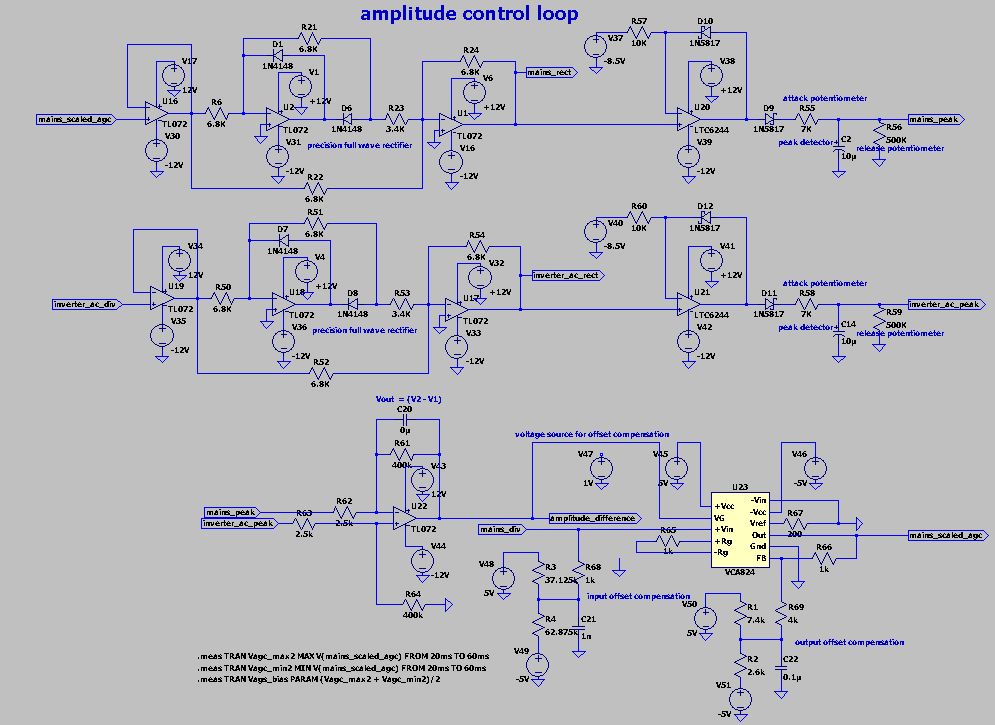
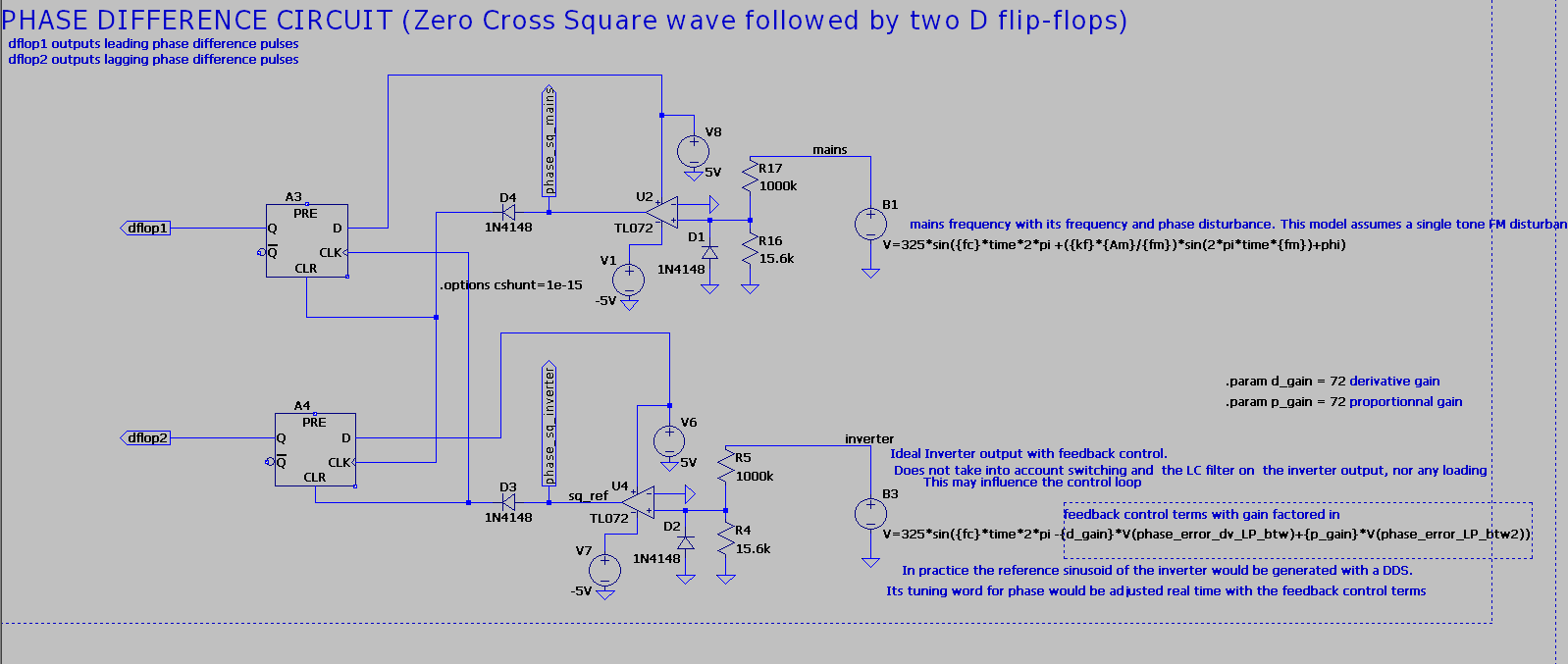
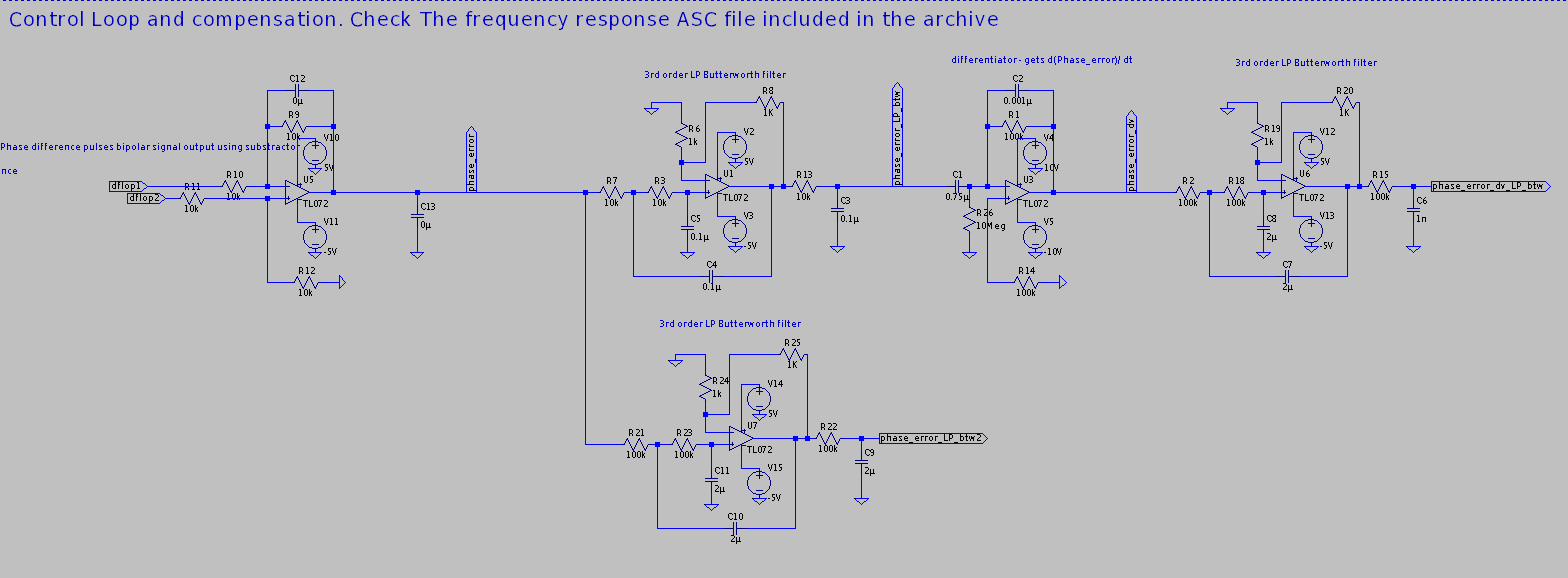
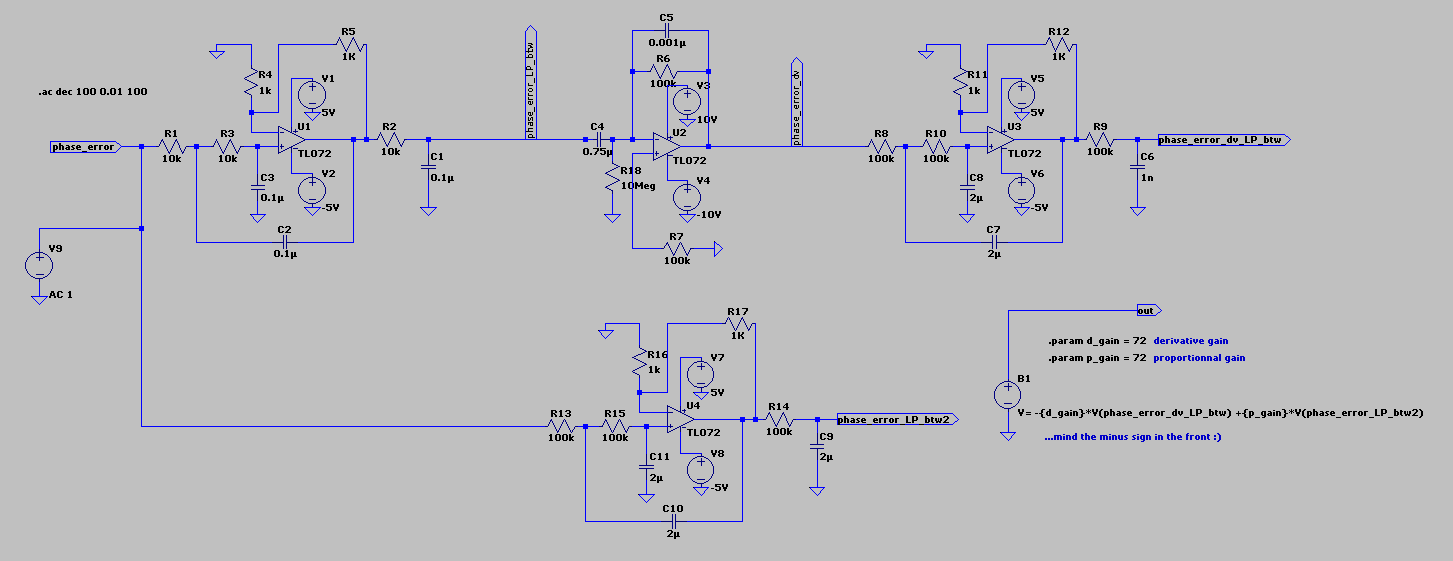
Lightweight ASCII English Text Stream Compression in Python.
NOTE : updated documentation and source code is available at :
https://github.com/rodv92/PLETSC
PLETSC
Lightweight english text stream compression, with word tokens, ngrams, session dictionaries and Huffmann for unknown words.
How to use :
git clone and decompress dics.zip in the current folder.
Syntax for compression :
python3 dicstrv.py -c txt_inputfile compressed_outputfile Reads txt_inputfile and writes compressed text stream to compressed_outputfile.
python3 dicstrv.py -c txt_inputfile Reads txt_input file and writes compressed output to stdout
Syntax for decompression :
python3 dicstrv.py -x compressed_inputfile txt_outputfile Reads compressed_inputfile and writes cleartext to txt_outputfile.
python3 dicstrv.py -x compressed_inputfile
Reads compressed_input file and writes cleartext output to stdout
Syntax to generate a compiled dictionary of ngrams :
python3 dicstrv.py -d cleartext_ngrams_inputfile compressed_ngrams
This is rarely used in normal operation.
NOTE: dictionary file count1_w.txt must be in the same directory as the script. outngrams.bin must be in the same directory as the script, if ngrams are used (secondpass=True)
Description :
This script is useful for ASCII English text stream compression. It’s pedantic (P in PLETSC stands for “pedantic”) because its final goal is to enforce a minima some English syntactic rules, such as whitespace after “,” but not before, Capitalization after a “.” etc… (but not grammar). Spell check will probably be recommended but should probably be done upstream (by another applicative layer), as it will ensure a better compression ratio – since it is based on words of the english dictionary.
Its compression method is primarily based on a token (words and punctuation) dictionary. It leverages frequency of modern english words:
- Words of the primary dictionary are sorted from most used to least used.
- The line number is used as an index. (+1) index 0 is reserved for whitespace.
It also uses adaptive length encoding (1-2-3 bytes) First 128 most used tokens are encoded on 1 byte, Next 16384 + 128 on 2 bytes. Next 2097152 + 16384 + 128 on 3 bytes.
The 3 byte address space is split in two :
- First part (when byte0 msb is 1 and byte1 msb is 1 and byte2 msb is 0) is further divided into two subspaces.
- The first subspace is for the remainder of the primary dictionary (it has 333 333 tokens).
- And the second subspace holds an Ngram dictionary (more on that later).
- Second part (when byte0 msb is 1 and byte1 msb is 1 and byte2 msb is 1) is further divided into two subspaces.
- First part is for a session dictionary. A session dictionary is used to hold repeating unknown tokens. there are 2097152 – 5 codes available for this use. Initially empty. Kept in ram, it is a SESSION dictionary. This session dictionary should not be required to be sent between two parties, as it can be reconstructed entirely from the compressed stream.
- Second part is only 5 codes, (TODO, for now just 1 code, and switch between Huffmann and no compression is done in a bool parameter) It is an escape sequence meaning that following bytes will be encoded wit the following methods :
- first code : As a stream of chars (no compression), plus a C style termination (chr(0)).
- second code : Huffmann encoding, lowercase only.
- third code : Huffmann, lowercase + uppercase or uppercase only.
- fourth code : Huffmann, lowercase + uppercase + numbers, or numbers only.
- fifth code : All printable ASCII space, mainly for passwords. Each of these codes tells what Huffmann tree to use.
Performance :
It offers a good compression ratio (between 2.6 and 3.0+), That is, Sizes in % of ORIGINAL size of around 33% to 38%, mainly depending on the lexical complexity or lexical archaism of the source text, and presence of unkwnown or misspelled words.
A higher lexical complexity, or archaic texts, that is, if the input text uses less common words – based on current usage – (2023), will yield lower compression ratios.
The compresion ratio is more or less stable : it is quite independent of text length.
This is contrary to block algorithms that suffer from low compression for small files because of a significant overhead. For larger corpuses, block algorithms usually perform better, and modern methods may use ML methods to provide context and adaptive encoding based on that, they’re usually slower.
This is why this algorithm is intended for stream compression (on the fly). However, its current implementation is based on reading files. and outputting to a file or stdout.
Compression speed (all options enabled)
For this test :
- File is call_of_cthulhu.txt, size uncompressed is 69 kB
- Compression speed around 23,3 kB/s on a Intel(R) Core(TM) i5 CPU M 520 @ 2.40GHz (computer from 2011), + SSD storage
Footprint (filesystem)
zipped size of count1_w.txt + outngrams.bin is 11 566 806 bytes unzipped size is : 31 327 633 bytes + 3 157 445 bytes = 34 485 078 bytes.
Footprint (memory)
To be determined
Dependecies
These Python modules are required :
codecs, nltk, re, bitstring, bitarray, struct, time, dahuffman
Requirements
Input text file must be ASCII (for now) or UTF-8 decodable to ASCII (English). It ignores conversion errors. Decoded file will be encoded in ASCII. It should be in English to get adequate conversion.
Both ends (sender and receiver) MUST have the SAME dictionaries and the SAME Huffmann tables, as these are not sent with the data.
Information about the dictionaries
The primary dictionary is based on the “count_1w.txt” english dictionary of 333 333 words, (words ordered by lexical prevalence) tweaked with added special characters also listed by order of prevalence and added english contractions, and with word count number stripped off.
The original primary dictionary file is available on : https://norvig.com/ngrams/
It also features a secondary (optional) compression pass based on a compiled dictionary named outngrams.bin.
It features compression for 4 and 5 word ngrams found in the first compression step stream. Ngrams of less than 4 words are deemed not interesting as the first pass will usually encode them on 3 bytes, the same sized as a compressed ngram.
Compression and decompression require the primary dictionary to be available, and the secondary if the boolean SecondPass is set to true, (by default).
The zip “dics.zip” already have a compiled version of these dictionaries.
More information
The algorithm is heavily commented in the code.
Field of application
Main applications could be messaging over low bandwidth links like POCSAG radio text, or JS8Call for HAM radio, and IoT.
However, note that the underlying digital mode should allow binary transmission (not only transmission of printable ASCII characters) for seamless integration.
TODO and ISSUES :
See comments in the code.
Main issues for now are syntactic rules and spurious whitespaces, absence of whitespaces were they should have been, problems with hyphenated tokens, spurious newlines, problems with some possessive forms, and special constructs besides emails and well formed URLs.
Ngrams Processing from scratch :
Useful if you want to tweak or create your own dictionaries, we’ll discuss mainly the outngrams.bin dictionary, as count_1w.txt tweaking is straightforward. Note that count1_w.txt should not be modified once outngrams.bin is generated, or you’ll have to rebuild outngrams.bin
A preparatory step is required to generate a compressed version of the ngrams files, if you want to do it from scratch :
First create the ngrams CSV using this code repo : https://github.com/orgtre/google-books-ngram-frequency/tree/main/python
The repo contains scripts that perform the download and concatenation of ngrams according to criterions you specify. Note that LETSC has limited space in the first subspace of the 3 byte. more or less 2097152 – 333333 I have created an ngram list of 1571125 ngrams. The distribution between the 4grams and 5grams is roughly 50%/50%
The resulting CSV files need to be further processed by our algorithm
The script that create outngrams.bin (the secondary compiled dictionary based on the primary dictionary and the ngrams csv files from google-books-ngram) is called ngrams_format_dic.py This script is commented for what each line does.
# LIGHTWEIGHT ENGLISH TEXT STREAM COMPRESSION (LETSC)
# (adaptive encoding length 1byte/2byte/3byte based on word dictionary with statistical prevalence ordering - count1_w.txt)
# Huffmann encoding for uknown tokens
# Enforces English syntax rules for punctuation
# Takes into account possessives and contractions
# Has URLs and e-mails processing rules, more to follow
# Second pass compression using a dictionary of the most frequent 4 N-Grams of English fiction.
#GPL 3 License
# www.skynext.tech
# Rodrigo Verissimo
# v0.92
# October 21th, 2023
# Python + packages Requirements
# Python 3.9
# nltk, bitarray, bitstring, re, dahuffmann
# Performance : ratios between x2.6 for Middle to Modern and elaborate English (ex: Shakespeare)
# Up to x3 and more for simple english.
# adapted for text messaging / streaming
# Requires the same dictionary on both channel endpoints.
# ALGORITHM. Very straightforward. (adaptive encoding length based on dictionary with statistical ordering)
#################################################################################
# First byte :
#if MSB is 0, a whole word is encoded on the first 7 bits of one byte only.
#This makes 127 possible words. These are reserved for the first 127 most used
#english words. punctuation also appears as a possible word
# Second byte :
#if MSB of first byte is 1, and MSB of second byte is 0, a whole word is encoded
# with the help of the 7 LSB of byte 1 plus the 7 LSB of byte 2.
# This makes room for the next 16384 most used english words.
# Third byte :
# if MSB of first byte is 1 and MSB of second byte is 1, and the MSB of third byte is 0
# a whole word is encoded
# with the help of the 7 + 7 + 7 = 21 bits (2 097 152 possible words)
# For now, the 3 byte address space is split into two 2 097 152 address spaces
# That is, the case of all 3 bytes MSB being 1 is treated separately.
# In this adress space, only a handful of codes are used as an escape sequence for particular
# Huffmann trees, see below.
#->
#load dictionary of english words from most used to least used.
#punctuation and special characters have been added with order of prevalence.
#punctuation frequency is from wikipedia corpus. (around 1.3 billion words)
#it has been normalized to the frequency of the 1/3 million word list based
#on the google web trillon word corpus. that is, frequencies for special chars have been multiplied by 788.39
#wikipedia punctuation is not optimized for chat, as it lower prevalence of chars like question marks
#that may appear more frequently in chat situations.
# the first tokenizer used does not separate any special character attached (without whitespace) to a word
# this will mostly result in an unknown word in the dictionary
# this key absence in the reverse dict will be catched and treated by another tokenizer (mainly for possessive
# forms and contractions)
#for possessives ex: "dog's bone" or plural "dogs' bones" a separate tokenizer is used to split into
# "dog" , "'s"
# "'s" and "'" also appear in the dictionary.
# ROADMAP
# remove whitespaces left of punctuation DONE
# manage new lines DONE
# manage websites and emails DONE
# TODO
# add spell check !
# TODO
# Remove spurious new lines that appear after encoding special sequences such mails or URLS
# DONE (basic Huffmann, some chars missing in tree)
# add Huffmann encoding for absent words in dictionary (neologisms,colloqualisms,dialects, or misspellings) DONE
# DONE
# TODO : test with more texts such as wikipedia XML and various authors works, to catch as much
# use cases and formatting issues that arise to improve the algorithm
# add adaptive Huffmann. use 4 Huffmann trees. (see below)
# Assuming there are 4 codes for hufmmann : hufmann lower case, hufmann lower + capitals, huffmann
# lower + capitals + numeric, all printable ASCII excluding whitespace : same as preceding category plus
# special chars.
# Chosing the tree to use would be done by string regex.
#DONE
# Detect UTF-8 and transcode to ASCII (potentially lossy)
#DONE
# TODO
# Dictionary Learn over time (re-shuffle the order of tokens)
# Without transmission of any info between parties
# Dangerous if sync is lost between the two parties
# TODO
# TODO
# optimize Huffmann part to remove the need for the chr(0) termination = scan for EOF sequence in Huffmann to get
# the Huffmann byte sequence length. TODO
# DONE
# Add second pass compression using word N-grams lookup table. (4 and 5 N-grams seem to be a good compromize)
# The idea is to encode 4 and 5 token substrings in a line by a single 3 byte code.
# There is plenty of room left in the 3 byte address space. For now, there is 333 333 - 16384 - 128 tokens used = 316821 tokens used
# from 4194304 - 3 total address space.
# DONE using 1 571 125 codes for a 50/50 mix of 4grams and 5grams.
# There is still at least 2million codes left.
# for now we plan 4 escape sequences for the selection of one of the 4 Huffmann trees.
# ngrams processing is first done with the create_ngrams_dic.sh script.
"""
python3 ngrams_format_dic.py 4grams_english-fiction.csv outngrams4.txt #remove counts and process contractions
python3 ngrams_format_dic.py 5grams_english-fiction.csv outngrams5.txt #remove counts and process contractions
python3 dicstrv4.py -d outngrams4.txt outngrams4.bin.dup #convert ngrams txt to compressed form
python3 dicstrv4.py -d outngrams5.txt outngrams5.bin.dup #convert ngrams txt to compressed form
awk '!seen[$0]++' outngrams4.bin.dup > outngrams4.bin #Remove spurious duplicates that may arise
awk '!seen[$0]++' outngrams5.bin.dup > outngrams5.bin #Remove spurious duplicates that may arise
sed -i '786001,$ d' outngrams4.bin # truncate to fit target address space
sed -i '786001,$ d' outngrams5.bin # truncate to fit target address space
cat outngrams4.bin outngrams5.bin > outngrams.bin # concatenate. this is our final form
cat outngrams.bin | awk '{ print length, bash $0 }' | sort -n -s | cut -d" " -f2- > sorted.txt # sort by size to have an idea of distribution
# ngrams that encode as less than 4 bytes have been pruned since the ratio is 1
"""
# DONE
# It is probable that the most used 4 tokens N-grams are based on already frequent words. that individually
# encode as 1 byte or two bytes.
# Worst case : all the 4 tokens are encoded in the 1 to 128 addres space, so they take a total 4 bytes.
# The resulting code will be 3 bytes, a deflate percent of 25%
# If one of the tokens is 2 byte (128 to 16384 -1 address space), then it uses 5 bytes.
# deflate percent is 40%
# The unknown is the statistical prevalence of two million 4 token N-grams.
# (ex: coming from english fiction corpus) in a standard chat text.
# First encode the google most frequent 4 and 5 N-grams csv file to replace the tokens in each N-gram by the corrsponding
# byte sequences from our codes in the count_1w.txt dictionary. This will be another pre-process script.
# The resulting new csv format will be :
# some 3 byte index = x04x09x23.
# The 3 byte index is simply the line number of the compressed ngram.
# read that in ram. Conservative Estimate 4 bytes + 3 bytes per entry 7 bytes * 2 000 000 = 14 Meg memory footprint.
# We already have a 4 MB * 3 12 Meg footprint from count_1w (estimate)
# Generate the inverse map dictionary (mapping sequences to 3 byte indexes)
# x04x09x23' = some 3 byte index
# Should not be a problem since there is a 1 to 1 relationship between the two
# Then perform a first pass compression.
# Then scan the first pass compression file using a 4 token sliding window.
# Contractions is a case that will have to be managed.
# If there are overlapping matches, chose the match that result in the best deflation, if any.
# If the unknown word escape codes appears, stop processing and resume after the escaped word
# Overall, replace the byte sequence by the corrsponding 3 byte sequence.
# DONE
import sys
import traceback
#print(len(sys.argv))
#op = (sys.argv[1]).encode("ascii").decode("ascii")
#print(op)
#quit()
if ((len(sys.argv) < 3) or (len(sys.argv) > 4)):
print("Syntax for compression :\n")
print("python3 dicstrv.py -c <txt_inputfile> <compressed_outputfile>")
print("Reads txt_inputfile and writes compressed text stream to compressed_outputfile.\n")
print("python3 dicstrv.py -c <txt_inputfile>")
print("Reads txt_input file and writes compressed output to stdout\n")
print("Syntax for decompression :\n")
print("python3 dicstrv.py -x <compressed_inputfile> <txt_outputfile>")
print("Reads compressed_inputfile and writes cleartext to txt_outputfile.\n")
print("python3 dicstrv.py -x <compressed_inputfile>\n")
print("Reads compressed_input file and writes cleartext output to stdout\n")
print("NOTE: dictionary file count1_w.txt must be in the same directory as the script.")
quit()
if (sys.argv[1] == "-c"):
compress = True
gendic = False
elif (sys.argv[1] == "-d"):
compress = True
gendic = True
elif (sys.argv[1] == "-x"):
compress = False
gendic = False
else:
print("unknown operation: " + str(sys.argv[0]) + " type 'python3 dicstrv3.py' for help")
if (len(sys.argv) == 3):
infile = sys.argv[2]
outfile = ''
if (len(sys.argv) == 4):
infile = sys.argv[2]
outfile = sys.argv[3]
import codecs
import nltk
from nltk.tokenize import TweetTokenizer
tknzr = TweetTokenizer()
import re
import bitstring
from bitarray import bitarray
import struct
import time
from dahuffman import HuffmanCodec
debug_on = False
debug_ngrams_dic = False
secondpass = True
use_huffmann = False
unknown_token_idx = 16384 + 128 + 2097152
def debugw(strdebug):
if (debug_on):
print(strdebug)
# Huffmann is only used for absent words in count1_w.txt dictionary
# General lower and upper case frequency combined as lowercase
codec_lower = HuffmanCodec.from_frequencies(
{'e' : 56.88, 'm' : 15.36,
'a' : 43.31, 'h' : 15.31,
'r' : 38.64, 'g' : 12.59,
'i' : 38.45, 'b' : 10.56,
'o' : 36.51, 'f' : 9.24,
't' : 35.43, 'y' : 9.06,
'n' : 33.92, 'w' : 6.57,
's' : 29.23, 'k' : 5.61,
'l' : 27.98, 'v' : 5.13,
'c' : 23.13, 'x' : 1.48,
'u' : 18.51, 'z' : 1.39,
'd' : 17.25, 'j' : 1,
'p' : 16.14, 'q' : 1
}
)
debugw(codec_lower.get_code_table())
# following is ASCII mixed upper and lower case frequency from an English writer from Palm OS PDA memos in 2002
# Credit : http://fitaly.com/board/domper3/posts/136.html
codec_upperlower = HuffmanCodec.from_frequencies(
{'A' : 0.3132,
'B' : 0.2163,
'C' : 0.3906,
'D' : 0.3151,
'E' : 0.2673,
'F' : 0.1416,
'G' : 0.1876,
'H' : 0.2321,
'I' : 0.3211,
'J' : 0.1726,
'K' : 0.0687,
'L' : 0.1884,
'M' : 0.3529,
'N' : 0.2085,
'O' : 0.1842,
'P' : 0.2614,
'Q' : 0.0316,
'R' : 0.2519,
'S' : 0.4003,
'T' : 0.3322,
'U' : 0.0814,
'V' : 0.0892,
'W' : 0.2527,
'X' : 0.0343,
'Y' : 0.0304,
'Z' : 0.0076,
'a' : 5.1880,
'b' : 1.0195,
'c' : 2.1129,
'd' : 2.5071,
'e' : 8.5771,
'f' : 1.3725,
'g' : 1.5597,
'h' : 2.7444,
'i' : 4.9019,
'j' : 0.0867,
'k' : 0.6753,
'l' : 3.1750,
'm' : 1.6437,
'n' : 4.9701,
'o' : 5.7701,
'p' : 1.5482,
'q' : 0.0747,
'r' : 4.2586,
's' : 4.3686,
't' : 6.3700,
'u' : 2.0999,
'v' : 0.8462,
'w' : 1.3034,
'x' : 0.1950,
'y' : 1.1330,
'z' : 0.0596
})
debugw(codec_upperlower.get_code_table())
# following is ASCII alpha numeric frequency from an English writer from Palm OS PDA memos in 2002
# Credit : http://fitaly.com/board/domper3/posts/136.html
codec_alphanumeric = HuffmanCodec.from_frequencies(
{'0' : 0.5516,
'1' : 0.4594,
'2' : 0.3322,
'3' : 0.1847,
'4' : 0.1348,
'5' : 0.1663,
'6' : 0.1153,
'7' : 0.1030,
'8' : 0.1054,
'9' : 0.1024,
'A' : 0.3132,
'B' : 0.2163,
'C' : 0.3906,
'D' : 0.3151,
'E' : 0.2673,
'F' : 0.1416,
'G' : 0.1876,
'H' : 0.2321,
'I' : 0.3211,
'J' : 0.1726,
'K' : 0.0687,
'L' : 0.1884,
'M' : 0.3529,
'N' : 0.2085,
'O' : 0.1842,
'P' : 0.2614,
'Q' : 0.0316,
'R' : 0.2519,
'S' : 0.4003,
'T' : 0.3322,
'U' : 0.0814,
'V' : 0.0892,
'W' : 0.2527,
'X' : 0.0343,
'Y' : 0.0304,
'Z' : 0.0076,
'a' : 5.1880,
'b' : 1.0195,
'c' : 2.1129,
'd' : 2.5071,
'e' : 8.5771,
'f' : 1.3725,
'g' : 1.5597,
'h' : 2.7444,
'i' : 4.9019,
'j' : 0.0867,
'k' : 0.6753,
'l' : 3.1750,
'm' : 1.6437,
'n' : 4.9701,
'o' : 5.7701,
'p' : 1.5482,
'q' : 0.0747,
'r' : 4.2586,
's' : 4.3686,
't' : 6.3700,
'u' : 2.0999,
'v' : 0.8462,
'w' : 1.3034,
'x' : 0.1950,
'y' : 1.1330,
'z' : 0.0596
})
debugw(codec_alphanumeric.get_code_table())
# following is Whole ASCII printable chars frequency except whitespace from an English writer from Palm OS PDA memos in 2002
# Credit : http://fitaly.com/board/domper3/posts/136.html
codec_all = HuffmanCodec.from_frequencies(
{'!' : 0.0072,
'\"' : 0.2442,
'#' : 0.0179,
'$' : 0.0561,
'%' : 0.0160,
'&' : 0.0226,
'\'' : 0.2447,
'(' : 0.2178,
')' : 0.2233,
'*' : 0.0628,
'+' : 0.0215,
',' : 0.7384,
'-' : 1.3734,
'.' : 1.5124,
'/' : 0.1549,
'0' : 0.5516,
'1' : 0.4594,
'2' : 0.3322,
'3' : 0.1847,
'4' : 0.1348,
'5' : 0.1663,
'6' : 0.1153,
'7' : 0.1030,
'8' : 0.1054,
'9' : 0.1024,
':' : 0.4354,
';' : 0.1214,
'<' : 0.1225,
'=' : 0.0227,
'>' : 0.1242,
'?' : 0.1474,
'@' : 0.0073,
'A' : 0.3132,
'B' : 0.2163,
'C' : 0.3906,
'D' : 0.3151,
'E' : 0.2673,
'F' : 0.1416,
'G' : 0.1876,
'H' : 0.2321,
'I' : 0.3211,
'J' : 0.1726,
'K' : 0.0687,
'L' : 0.1884,
'M' : 0.3529,
'N' : 0.2085,
'O' : 0.1842,
'P' : 0.2614,
'Q' : 0.0316,
'R' : 0.2519,
'S' : 0.4003,
'T' : 0.3322,
'U' : 0.0814,
'V' : 0.0892,
'W' : 0.2527,
'X' : 0.0343,
'Y' : 0.0304,
'Z' : 0.0076,
'[' : 0.0086,
'\\' : 0.0016,
']' : 0.0088,
'^' : 0.0003,
'_' : 0.1159,
'`' : 0.0009,
'a' : 5.1880,
'b' : 1.0195,
'c' : 2.1129,
'd' : 2.5071,
'e' : 8.5771,
'f' : 1.3725,
'g' : 1.5597,
'h' : 2.7444,
'i' : 4.9019,
'j' : 0.0867,
'k' : 0.6753,
'l' : 3.1750,
'm' : 1.6437,
'n' : 4.9701,
'o' : 5.7701,
'p' : 1.5482,
'q' : 0.0747,
'r' : 4.2586,
's' : 4.3686,
't' : 6.3700,
'u' : 2.0999,
'v' : 0.8462,
'w' : 1.3034,
'x' : 0.1950,
'y' : 1.1330,
'z' : 0.0596,
'{' : 0.0026,
'|' : 0.0007,
'}' : 0.0026,
'~' : 0.0003,
})
debugw(codec_all.get_code_table())
#quit()
def check_file_is_utf8(filename):
debugw("checking encoding of:")
debugw(filename)
try:
f = codecs.open(filename, encoding='utf-8', errors='strict')
for line in f:
pass
debugw("Valid utf-8")
return True
except UnicodeDecodeError:
debugw("invalid utf-8")
return False
def find_huffmann_to_use(token):
if(not use_huffmann):
debugw("do not use Huffmann, encode char by char")
return 0
not_alllower = re.search("[^a-z]")
if(not not_alllower):
debugw("all lower case")
return 1
not_alllowerorupper = re.search("[^A-Za-z]")
if(not not_alllowerorupper):
debugw("all lower or upper")
return 2
not_alllalphanumeric = re.search("[^A-Za-z0-9]")
if(not not_alllalphanumeric):
debugw("all alpha numeric")
return 3
else:
debugw("all printable, except whitespace")
return 4
def encode_unknown(token,treecode):
if (treecode == 0):
bytes_unknown = bytearray()
for charidx in range(0, len(token)):
debugw("appending chars..")
debugw(token[charidx])
# only append if it is not an unexpected termination in the unknown token
if (not ord(token[charidx]) == 0):
bytes_unknown.append(ord(token[charidx]))
else:
debugw("unexpected termination chr(0) in unknown token, discarding character")
return bytes_unknown
if (treecode == 1):
return codec_lower.encode(token)
if (treecode == 2):
return codec_upperlower.encode(token)
if (treecode == 3):
return codec_alphanumeric.encode(token)
if (treecode == 4):
return codec_all.encode(token)
def decode_unknown(bytetoken,treecode):
if (treecode == 1):
return codec_lower.decode(bytetoken)
if (treecode == 2):
return codec_upperlower.decode(bytetoken)
if (treecode == 3):
return codec_alphanumeric.decode(bytetoken)
if (treecode == 4):
return codec_all.decode(bytetoken)
def compress_token_or_subtoken(compressed,line_token,token_of_line_count,lentoken,gendic):
global unknown_token_idx
try:
# is the token in english dictionary ?
debugw("line_token:" + line_token)
tokenid = engdictrev[line_token]
subtokensid = [tokenid]
except:
debugw("unknown word, special chars adjunct, or possessive form")
# let's try to split the unknown word from possible adjunct special chars
# for this we use another tokenizer
subtokens = nltk.word_tokenize(line_token)
if (len(subtokens) == 1):
# no luck...
# TODO : do not drop the word silently, encode it !
# If we encode a ngram dic, skip ngrams with unknown tokens in the primary dic.
# and return empty bytearray to signify ngram compression failure
if(gendic):
compressed = bytearray()
debugw("gendic : unknown word")
return (compressed, token_of_line_count)
debugw("unknown word")
#AMEND dictionary
# add this unknown subtoken to a session dic so it can be recalled.
debugw("unknown word: " + subtokens[0] + " adding to session dic at id: " + str(unknown_token_idx))
debugw("unknown word, adding to session dic at id: " + str(unknown_token_idx))
engdictrev[subtokens[0]] = unknown_token_idx
engdict[unknown_token_idx] = subtokens[0]
unknown_token_idx += 1
#subtokensid = [4194304 - 1] # subtoken code for unknown word escape sequence.
subtokensid = [4194303 - find_huffmann_to_use(subtokens[0])]
#print(subtokensid)
#continue
else:
debugw("possible special char found")
subtokensid = []
for subtoken in subtokens:
debugw("subtoken=")
debugw(subtoken)
try:
subtokensid.append(engdictrev[subtoken])
except:
# no luck...
# TODO : do not drop the word silently, encode it !
# If we encode a ngram dic, skip ngrams with unknown tokens in the primary dic.
# and return empty bytearray to signify ngram compression failure
if(gendic):
compressed = bytearray()
debugw("gendic : unknown word")
return (compressed, token_of_line_count)
debugw("unknown subtoken")
subtokensid.append(4194303 - find_huffmann_to_use(subtoken))
#subtokensid.append(4194304 - 1)
# add this unknown subtoken to a session dic so it can be recalled.
#AMEND dictionary
# add this unknown subtoken to a session dic so it can be recalled.
debugw("unknown subtoken: " + subtoken + " adding to session dic at id: " + str(unknown_token_idx))
debugw("unknown subtoken, adding to session dic at id: " + str(unknown_token_idx))
engdictrev[subtoken] = unknown_token_idx
engdict[unknown_token_idx] = subtoken
unknown_token_idx += 1
#continue
subtokenidx = 0
for subtokenid in subtokensid:
debugw("subtokenid=")
debugw(subtokenid)
# maximum level of token unpacking is done
if(subtokenid < 128):
debugw("super common word")
debugw(engdict[subtokenid])
#convert to bytes
byte0 = subtokenid.to_bytes(1, byteorder='little')
debugw("hex:")
debugw(byte0.hex())
#append to bytearray
compressed.append(byte0[0])
if(128 <= subtokenid < 16384 + 128):
debugw("common word")
#remove offset
debugw(engdict[subtokenid])
subtokenid -= 128
#convert to bytes1 (array of 2 bytes)
bytes1 = subtokenid.to_bytes(2,byteorder='little')
debugw("".join([f"\\x{byte:02x}" for byte in bytes1]))
#convert to bitarray
c = bitarray(endian='little')
c.frombytes(bytes1)
debugw(c)
# set msb of first byte to 1 and shift the more significant bits up.
c.insert(7,1)
debugw(c)
# remove excess bit
del c[16:17:1]
debugw(c)
# append our two tweaked bytes to the compressed bytearray
compressed.append((c.tobytes())[0])
compressed.append((c.tobytes())[1])
#if(16384 +128 <= subtokenid < 4194304 - 1):
if(16384 +128 <= subtokenid < 2097152 + 16384 + 128):
debugw("rare word")
# remove offset
debugw(engdict[subtokenid])
subtokenid -= (16384 + 128)
#convert to bytes1 (array of 3 bytes)
bytes2 = subtokenid.to_bytes(3,byteorder='little')
debugw("".join([f"\\x{byte:02x}" for byte in bytes2]))
#convert to bitarray
c = bitarray(endian='little')
c.frombytes(bytes2)
debugw(c)
# set msb of first byte to 1 and shift the bits above up.
c.insert(7,1)
debugw(c)
# set msb of second byte to 1 and shift the bits above up.
c.insert(15,1)
debugw(c)
# remove two excess bits that arose from our shifts
del c[24:26:1]
debugw(c)
# append our three tweaked bytes to the compressed bytearray
compressed.append((c.tobytes())[0])
compressed.append((c.tobytes())[1])
compressed.append((c.tobytes())[2])
#if(16384 +128 <= subtokenid < 4194304 - 1):
if(16384 +128 + 2097152 <= subtokenid < 4194304 - 5):
debugw("unknown word from session DIC")
# remove offset
debugw(engdict[subtokenid])
subtokenid -= (2097152 + 16384 + 128)
#convert to bytes1 (array of 3 bytes)
bytes2 = subtokenid.to_bytes(3,byteorder='little')
debugw("".join([f"\\x{byte:02x}" for byte in bytes2]))
#convert to bitarray
c = bitarray(endian='little')
c.frombytes(bytes2)
debugw(c)
# set msb of first byte to 1 and shift the bits above up.
c.insert(7,1)
debugw(c)
# set msb of second byte to 1 and shift the bits above up.
c.insert(15,1)
debugw(c)
# set msb of third byte to 1 and shift the bits above up.
c.insert(23,1)
debugw(c)
# remove three excess bits that arose from our shifts
del c[24:27:1]
debugw(c)
# append our three tweaked bytes to the compressed bytearray
compressed.append((c.tobytes())[0])
compressed.append((c.tobytes())[1])
compressed.append((c.tobytes())[2])
#if(subtokenid == (4194304 - 1)):
if(subtokenid in range(4194299,4194304)):
#compressed.append(255)
#compressed.append(255)
#compressed.append(255)
debugw("huffmann tree code :" + str(subtokenid))
# TODO : Use Huffmann tree instead of byte->byte encoding.
#convert to bytes1 (array of 3 bytes)
bytes2 = subtokenid.to_bytes(3,byteorder='little')
debugw("".join([f"\\x{byte:02x}" for byte in bytes2]))
#convert to bitarray
c = bitarray(endian='little')
c.frombytes(bytes2)
debugw(c)
# set msb of first byte to 1 and shift the bits above up.
c.insert(7,1)
debugw(c)
# set msb of second byte to 1 and shift the bits above up.
c.insert(15,1)
debugw(c)
# no need to set msb of third byte to 1 since the range will take care of it.
#c.insert(23,1)
#debugw(c)
# remove two excess bits that arose from our shifts
del c[24:26:1]
debugw(c)
# append our three tweaked bytes that signify the huffmann tree to use to the compressed bytearray
compressed.append((c.tobytes())[0])
compressed.append((c.tobytes())[1])
compressed.append((c.tobytes())[2])
if (len(subtokens) == 1):
if(not use_huffmann):
debugw("encoding unkown word")
#for charidx in range(0, len(line_token)):
# debugw("appending chars..")
# debugw(line_token[charidx])
# compressed.append(ord(line_token[charidx]))
compressed.extend(encode_unknown(line_token,0))
else:
debugw("encoding unkown line token with Huffmann")
huffmann_tree_code = -(subtokenid - 4194303)
compressed.extend(encode_unknown(line_token,huffmann_tree_code))
else:
if(not use_huffmann):
debugw("encoding unkown subtoken")
#for charidx in range(0, len(subtokens[subtokenidx])):
# debugw("appending chars..")
# debugw((subtokens[subtokenidx])[charidx])
# compressed.append(ord((subtokens[subtokenidx])[charidx]))
compressed.extend(encode_unknown(subtokens[subtokenidx],0))
else:
debugw("encoding unkown subtoken with Huffmann")
debugw(subtokens[subtokenidx])
#huffmann_tree_code = find_huffmann_to_use(subtokens[subtokenidx])
huffmann_tree_code = -(subtokenid - 4194303)
compressed.extend(encode_unknown(subtokens[subtokenidx],huffmann_tree_code))
compressed.append(0) # terminate c string style
subtokenidx += 1
token_of_line_count += 1
debugw("token of line count")
debugw(token_of_line_count)
debugw("lentoken")
debugw(lentoken)
if((token_of_line_count == lentoken) and (not gendic)):
# newline
debugw("append new line")
compressed.append(0)
#quit()
return (compressed,token_of_line_count)
def compress_tokens(tokens,gendic):
#time.sleep(0.001)
# Init byte array
compressed = bytearray()
debugw("tokens are:")
debugw(tokens)
for token in tokens:
debugw("token is:")
debugw(token)
token_of_line_count = 0
# start compression run
if(not len(token) and (not gendic)):
debugw("paragraph")
compressed.append(0)
#compressed.append(0)
#quit()
lentoken = len(token)
if (not gendic):
for line_token in token:
(compressed, token_of_line_count) = compress_token_or_subtoken(compressed,line_token,token_of_line_count,lentoken,gendic)
else:
(compressed, token_of_line_count) = compress_token_or_subtoken(compressed,token,token_of_line_count,lentoken,gendic)
if(not len(compressed)):
debugw("unknown word in gendic sequence, aborting")
compressed = bytearray()
return compressed
# dump whole compressed stream
debugw("compressed ngram is=")
debugw(compressed.hex())
debugw("compressed ngram byte length is=")
debugw(len(compressed))
return compressed
def compress_second_pass(compressed):
ngram_compressed = bytearray()
ngram_length = 0
ngram_byte_length = 0
index_jumps = []
candidates = []
idx = 0
# second pass main loop
#debugw("compressed=")
#debugw(compressed)
while (idx < len(compressed)):
debugw("second pass idx=")
debugw(idx)
idxchar = 0
reset_ngram = False
debugw("indexjumps=")
debugw(index_jumps)
if(not (compressed[idx] & 128)):
ngram_compressed.append(compressed[idx])
debugw("".join([f"\\x{byte:02x}" for byte in ngram_compressed]))
debugw("super common ext")
idx += 1
index_jumps.append(1)
ngram_byte_length += 1
elif((compressed[idx] & 128) and (not (compressed[idx+1] & 128))):
ngram_compressed.extend(compressed[idx:idx+2])
debugw("".join([f"\\x{byte:02x}" for byte in ngram_compressed]))
debugw("common ext")
idx += 2
index_jumps.append(2)
ngram_byte_length += 2
elif((compressed[idx] & 128) and (compressed[idx+1] & 128) and (not compressed[idx+2] & 128)):
ngram_compressed.extend(compressed[idx:idx+3])
debugw("".join([f"\\x{byte:02x}" for byte in ngram_compressed]))
debugw("rare ext")
idx += 3
index_jumps.append(3)
ngram_byte_length += 3
elif((compressed[idx] == 255) and (compressed[idx+1] == 255) and (compressed[idx+2] == 255)):
# TODO : take into account 4 escape sequences instead of only one.
#reset ngram_compressed
char = compressed[idx+3]
debugw("unknown token sequence detected")
#print(char)
#str = ""
idxchar = 0
while(char != 0):
idxchar += 1
char = compressed[idx+3+idxchar]
debugw("char=")
debugw(char)
debugw("end of unknown token sequence detected at idx:")
idx += (3 + idxchar)
debugw(idx)
index_jumps.append(3 + idxchar)
ngram_length -= 1
reset_ngram = True
elif((compressed[idx] & 128) and (compressed[idx+1] & 128) and (compressed[idx+2] & 128)):
# Session DIC space, breaks ngram construction.
debugw("session DIC space, we break ngram construction")
idx += 3
index_jumps.append(3)
ngram_length -= 1
reset_ngram = True
ngram_length += 1
debugw("indexjumps=")
debugw(index_jumps)
debugw("ngram_length")
debugw(ngram_length)
if (((ngram_length == 3) and (ngram_byte_length > 3)) or (ngram_length == 4)):
# if there are contractions, apparent ngram length will be one token less and potentially present in N4 ngrams
# try to replace the ngram if it exists, and only if ngram_byte_length is > 3, otherwise there will be no compression gain.
# save index jumps for rewind operations.
# TO BE CONTINUED .....
try:
ngram_compressed_no_ascii = "".join([f"\\x{byte:02x}" for byte in ngram_compressed])
ngram_compressed_no_ascii = ngram_compressed_no_ascii.replace("\\","")
debugw(ngram_compressed_no_ascii)
code = ngram_dict[ngram_compressed_no_ascii]
debugw("****FOUND*****")
ratio = ngram_byte_length/3 # all ngrams are encoded in a 3 byte address space, hence div by 3
removebytes = ngram_byte_length
if(idxchar):
insertpos = idx - ngram_byte_length - (3 + idxchar)
else:
insertpos = idx - ngram_byte_length
candidates.append((code,insertpos,removebytes,ratio))
except:
#traceback.print_exc()
debugw("no luck 3N/4N")
# reset all ngram data
ngram_length = 0
ngram_byte_length = 0
ratio = 0
removebytes = 0
ngram_compressed = bytearray()
#rewind...and retry a new ngram window from initial token index + one token shift
#BUG HERE !!
debugw("indexjumps=")
debugw(index_jumps)
#time.sleep(0.1)
debugw("lastindexjumps_except_first=")
debugw(index_jumps[-len(index_jumps)+1:])
debugw("index_before_rewind=")
debugw(idx)
idx -= sum(index_jumps[-len(index_jumps)+1:])
index_jumps = []
debugw("idx after rewind=")
debugw(idx)
elif (reset_ngram):
debugw("ngram reset : unknown token starts before ngram_length 3 or 4")
ngram_length = 0
ngram_byte_length = 0
ratio = 0
removebytes = 0
#do not rewind : reset pos after unknown sequence
index_jumps = []
return candidates
def process_candidates_v2(candidates):
#here we scan all candidates.
#if there are overlaps, we select the candidate with the best ratio, if any.
#The result is a reduced list of candidates data.
#Next we recreate the compressed stream and replace the bytes at insertpos by the candidate code
debugw(candidates)
candidates_reduced = []
idx_reduced = 0
idx = 0
deleted_candidates_number = 0
mutual_overlaps = []
overlap_idx = 0
while(idx < len(candidates)):
code = candidates[idx][0]
insertpos = candidates[idx][1]
removebytes = candidates[idx][2]
ratio = candidates[idx][3]
first_overlap = True
for idx_lookahead in range(idx+1,len(candidates)):
code_lookahead = candidates[idx_lookahead][0]
insertpos_lookahead = candidates[idx_lookahead][1]
removebytes_lookahead = candidates[idx_lookahead][2]
ratio_lookahead = candidates[idx_lookahead][3]
if((insertpos + removebytes - 1) >= insertpos_lookahead):
debugw("overlap!")
debugw(code)
debugw(code_lookahead)
#add mutually overlapping indexes to an array
if(first_overlap):
mutual_overlaps.append([idx])
mutual_overlaps[overlap_idx].append(idx_lookahead)
first_overlap = False
else:
# case for a mutual overlap of at least 3 ngrams
debugw("len mutual overlap:")
debugw(len(mutual_overlaps))
debugw("overlap_idx")
debugw(overlap_idx)
mutual_overlaps[overlap_idx].append(idx_lookahead)
overlap_idx += 1
else:
#end of mutual overlap (current lookahead is not overlapping with original idx)
break
idx += 1
#keep best ratio from all overlap lists
keep_idxs = []
remove_idx_shift = 0
for overlap in mutual_overlaps:
prev_candidate_ratio = 0
for candidate_idx in overlap:
debugw("candidate_idx:")
debugw(candidate_idx)
candidate_ratio = candidates[candidate_idx - remove_idx_shift][3]
if (candidate_ratio >= prev_candidate_ratio):
keep_idx = candidate_idx
prev_candidate_ratio = candidate_ratio
keep_idxs.append(keep_idx)
for candidate_idx in overlap:
if(candidate_idx != keep_idx):
debugw("candidate len:")
debugw(len(candidates))
debugw("will delete idx:")
debugw(str(candidate_idx - remove_idx_shift))
del candidates[candidate_idx - remove_idx_shift]
deleted_candidates_number += 1
debugw("deleted idx:")
debugw(str(candidate_idx - remove_idx_shift))
remove_idx_shift += 1
#keep the best ratio only from the list of mutual overlaps
if (deleted_candidates_number > 0):
debugw("recursive")
deleted_candidates_number = 0
process_candidates_v2(candidates)
#need to exit recursion when len candidates stops decreasing
return candidates
def ngram_insert_reserved_bits(ngram_compressed):
debugw("".join([f"\\x{byte:02x}" for byte in ngram_compressed]))
#convert to bitarray
c = bitarray(endian='little')
c.frombytes(ngram_compressed)
debugw(c)
# set msb of first byte to 1 and shift the bits above up.
c.insert(7,1)
debugw(c)
# set msb of second byte to 1 and shift the bits above up.
c.insert(15,1)
debugw(c)
# remove two excess bits that arose from our shifts
del c[24:26:1]
debugw(c)
# replace the original ngram_compressed bytearray with our tweaked bytes
ngram_compressed = bytearray()
ngram_compressed.append((c.tobytes())[0])
ngram_compressed.append((c.tobytes())[1])
ngram_compressed.append((c.tobytes())[2])
return ngram_compressed
def replace_candidates_in_processed(candidates,processed):
byteshift = 0
shiftcode = 0
for candidate in candidates:
insertpos = candidate[1] - byteshift
removebytes = candidate[2]
del processed[insertpos:insertpos + removebytes]
byteshift += removebytes
## first we need to convert candidate code to proper 3 byte format
# we add our 4 ngram code space at a 2^20 shift in the 3 bytes address space.
shifted_code = 524416 + candidate[0]
# now we convert our shifted ngram code to a byte sequence in the compressed format
bytes_shiftedcode = shifted_code.to_bytes(3, byteorder='little')
# print it
debugw(bytes_shiftedcode)
# tweak the bytes to insert reserved bits for 1/2/3 bytes variable length encoding
# compliance.
bytes_shiftedcode = ngram_insert_reserved_bits(bytes_shiftedcode)
# print it
debugw(bytes_shiftedcode)
# now we insert it at the position of the non-compressed ngram
processed[insertpos:insertpos] = bytes_shiftedcode
# we added 3 bytes, we have to compensate to keep future insertpos valid.
byteshift -= 3
return processed
def ngram_process_rules(subtokens):
### VARIOUS DETOKENIZER CLEANUP/FORMATTING OPERATIONS
processed_ngram_string = ""
capitalize = False
token_idx = 0
for token in subtokens:
if(capitalize):
token = token.capitalize()
capitalize = False
# English syntactic rules : remove whitespace left of "!?."
# and enforce capitalization on first non whitespace character following.
if (re.match("[!\?\.]",token)):
processed_ngram_string += token
capitalize = True
# English syntactic rules : remove whitespace left of ",;:"
elif (re.match("[,;:]",token)):
processed_ngram_string += token
capitalize = False
# append whitespace left of added token
else:
processed_ngram_string = processed_ngram_string + " " + token
token_idx += 1
if(len(subtokens) == token_idx):
debugw("last token of ngram")
processed_ngram_string += " "
return processed_ngram_string
def decompress_ngram_bytes(compressed):
idx = 0
detokenizer_ngram = []
while(idx < len(compressed)):
if(not (compressed[idx] & 128)):
# current index byte msb is at 0,
# it is one of the 128 first tokens in the dictionary.
debugw("super common word")
#decode in place
inta = compressed[idx]
detokenizer_ngram.append(engdict[inta])
idx += 1
elif((compressed[idx] & 128) and (not (compressed[idx+1] & 128))):
# current index byte msb is at 1, and next byte msb is at 0.
# it is one of the 16384 next tokens in the dictionary.
debugw("common word")
# populate bitarray from the two bytes
c = bitarray(endian='little')
c.frombytes(compressed[idx:idx+2])
debugw(c)
# remove first byte msb (shift down the bits above)
del c[7]
debugw(c)
# convert bytes array to 16 bit unsigned integer
inta = (struct.unpack("<H", c.tobytes()))[0]
# add offset back so we get a valid dictionary key
inta += 128
# print word
detokenizer_ngram.append(engdict[inta])
# increment byte counter with step 2, we processed 2 bytes.
idx += 2
#elif((compressed[idx] & 128) and (compressed[idx+1] & 128)):
elif((compressed[idx] & 128) and (compressed[idx+1] & 128) and (not compressed[idx+2] & 128)):
# current index byte msb is at 1, and next byte mbs is at 1.
# it is one of the 4194304 next tokens in the dictionary.
debugw("rare word")
chunk = compressed[idx:idx+3]
# populate bitarray from the three bytes
c = bitarray(endian='little')
#c.frombytes(compressed[idx:idx+3])
c.frombytes(chunk)
debugw(c)
# remove second byte msb (shift down the bits above)
del c[15]
debugw(c)
# remove first byte msb (shift down the bits above)
del c[7]
debugw(c)
c.extend("0000000000")
# pad to 4 bytes (32 bit integer format) : 3 bytes + 10 bits
# because we previously removed two bits with del c[15] and del c[7]
debugw(c)
# convert bytes array to 32 bit unsigned integer
inta = (struct.unpack("<L", c.tobytes()))[0]
inta += (16384 + 128)
detokenizer_ngram.append(engdict[inta])
# increment byte counter with step 3, we processed 3 bytes.
idx += 3
return detokenizer_ngram
###INLINE START###
#downloading tokenizer model if missing
nltk.download('punkt')
#opening the english dict of most used 1/3 million words from google corpus of 1 trillion words.
#special characters have been added with their respective prevalence (from wikipedia corpus)
#contractions also have been added in their form with a quote just after (next line) the form
# without quote. ex : next line after "dont" appears "don't"
file1 = open('count_1w.txt', 'r')
Lines = file1.readlines()
#initializing Python dicts
count = 1
engdict = {}
engdictrev = {}
# special case : byte val 0 is equal to new line.
# TODO : make sure that windows CRLF is taken care of.
engdict[0] = "\n"
engdictrev["\n"] = 0
# populating dicts
for line in Lines:
# Strips the newline character
engdict[count] = line.strip()
engdictrev[line.strip()] = count
count += 1
### populating ngram dict
filengrams = open('outngrams.bin', 'rt')
ngramlines = filengrams.readlines()
ngram_dict = {}
ngram_dict_rev = {}
count = 0
# populating dicts
for ngramline in ngramlines:
# Strips the newline character
#keystr = "".join([f"\\x{byte:02x}" for byte in ngramline.strip()])
#keystr = keystr.replace("\\","")
#if(count == 71374):
keystr = ngramline.strip()
#print(ngramline.strip())
#print(keystr)
#quit()
ngram_dict_rev[count] = keystr
ngram_dict[keystr] = count
count += 1
idx = 0
debugw("first ngram in dict:")
test = ngram_dict_rev[0]
debugw(test)
debugw(ngram_dict[test])
count = 0
if (compress):
tokens = []
# check if file is utf-8
if(check_file_is_utf8(infile)):
with codecs.open(infile, 'r', encoding='utf-8') as utf8_file:
# Read the content of the UTF-8 file and transcode it to ASCII
# encode('ascii','ignore') MAY replace unknown char with chr(0)
# We don't want that, as it is a termination char for unknown strings.
# on the other hand backslashreplace replaces too much chars that could be transcribed
# the best option for now it check for chr(0) presence before writing the unknown token representation.
ascii_content = utf8_file.read().encode('ascii', 'ignore').decode('ascii')
#debugw(ascii_content)
Linesin = ascii_content.splitlines()
if(debug_on):
outfile_ascii = infile + ".asc"
with codecs.open(outfile_ascii, "w", encoding='ascii') as ascii_file:
ascii_file.write(ascii_content)
else:
# Reading file to be compressed
file2 = open(infile,'r')
#text = file2.read()
Linesin = file2.readlines()
if(gendic):
if(len(outfile)):
fh = open(outfile, 'wt')
lineidx = 0
for line in Linesin:
line = line.lower()
# First pass tokenizer (does not split adjunct special chars)
line_tokens = tknzr.tokenize(line)
#debugw(line_tokens)
if( not gendic):
tokens.append(line_tokens)
else:
compressed = compress_tokens(line_tokens,gendic)
if(len(outfile) and len(compressed)):
# write compressed binary stream to file if supplied in args or to stdout otherwise.
hexstr = "".join([f"\\x{byte:02x}" for byte in compressed])
hexstr = hexstr.replace("\\","")
fh.write(hexstr)
if(debug_ngrams_dic):
fh.write("\t")
strline = str(lineidx)
fh.write(strline)
fh.write("\n")
else:
sys.stdout.buffer.write(compressed)
sys.stdout.buffer.write(b"\n")
lineidx += 1
#line_tokens.append("\n")
#tokens = tokens + line_tokens
debugw(tokens)
if (not gendic):
compressed = compress_tokens(tokens,gendic)
if(secondpass):
candidates = compress_second_pass(compressed)
debugw("candidates:")
debugw(candidates)
processed_candidates = process_candidates_v2(candidates)
debugw("processed candidates:")
debugw(processed_candidates)
compressed = replace_candidates_in_processed(processed_candidates,compressed)
# write compressed binary stream to file if supplied in args or to stdout otherwise.
if(len(outfile)):
with open(outfile, 'wb') as fh:
fh.write(compressed)
else:
sys.stdout.buffer.write(compressed)
for sessidx in range(2113664,unknown_token_idx):
debugw("session_index:" + str(sessidx))
debugw(engdict[sessidx])
debugw(engdictrev[engdict[sessidx]])
debugw("session_index:" + str(sessidx))
fh.close()
# decompress mode
else:
# decoding part
debugw("decoding...")
detokenizer = []
detokenizer_idx = 0
if(len(infile)):
with open(infile, 'rb') as fh:
compressed = bytearray(fh.read())
idx = 0
#FirstCharOfLine = 1
CharIsUpperCase = 1
#CharIsUpperCase2 = 0
# main decoding loop
while (idx < len(compressed)):
# write each byte
debugw(hex(compressed[idx]))
#if( (idx > 0) and compressed[idx] == 0 and compressed[idx - 1] == 0):
#find len of consecutive 0 chars
if(idx < len(compressed) -1):
if((compressed[idx] == 0) and (compressed[idx+1] != 0)):
#FirstCharOfLine = 1
CharIsUpperCase = 1
elif(CharIsUpperCase == 1):
#FirstCharOfLine = 2
CharIsUpperCase = 2
if(len(detokenizer) > 0):
### VARIOUS DETOKENIZER CLEANUP/FORMATTING OPERATIONS
#ensure this is not the end of an ngram. ngrams necessarily contain whitespaces
if (not re.search(" ",detokenizer[detokenizer_idx-2])):
# English syntactic rules : remove whitespace left of "!?."
# and enforce capitalization on first non whitespace character following.
if (re.match("[!\?\.]",detokenizer[detokenizer_idx-2]) and detokenizer_idx > 2):
del detokenizer[detokenizer_idx-3]
detokenizer_idx -= 1
if(CharIsUpperCase != 1):
CharIsUpperCase = 2
# English syntactic rules : remove whitespace left of ",;:"
if (re.match("[,;:]",detokenizer[detokenizer_idx-2]) and detokenizer_idx > 2):
del detokenizer[detokenizer_idx-3]
detokenizer_idx -= 1
# URL/URI detected, remove any spurious whitespace before "//"
if (re.match("^\/\/",detokenizer[detokenizer_idx-2]) and detokenizer_idx > 2):
del detokenizer[detokenizer_idx-3]
detokenizer_idx -= 1
# E-mail detected, remove whitespaces left and right of "@"
if (re.match("@",detokenizer[detokenizer_idx-2]) and detokenizer_idx > 2):
del detokenizer[detokenizer_idx-3]
detokenizer_idx -= 1
del detokenizer[detokenizer_idx-1]
detokenizer_idx -= 1
if(not (compressed[idx] & 128)):
# current index byte msb is at 0,
# it is one of the 128 first tokens in the dictionary.
debugw("super common word")
#decode in place
inta = compressed[idx]
if(CharIsUpperCase == 2):
detokenizer.append(engdict[inta].capitalize())
detokenizer_idx += 1
CharIsUpperCase = 0
else:
detokenizer.append(engdict[inta])
detokenizer_idx += 1
# print to stdout
if(CharIsUpperCase != 1):
detokenizer.append(" ")
detokenizer_idx += 1
debugw(engdict[inta])
idx += 1
elif((compressed[idx] & 128) and (not (compressed[idx+1] & 128))):
# current index byte msb is at 1, and next byte msb is at 0.
# it is one of the 16384 next tokens in the dictionary.
debugw("common word")
# populate bitarray from the two bytes
c = bitarray(endian='little')
c.frombytes(compressed[idx:idx+2])
debugw(c)
# remove first byte msb (shift down the bits above)
del c[7]
debugw(c)
# convert bytes array to 16 bit unsigned integer
inta = (struct.unpack("<H", c.tobytes()))[0]
# add offset back so we get a valid dictionary key
inta += 128
# print word
if(CharIsUpperCase == 2):
detokenizer.append(engdict[inta].capitalize())
detokenizer_idx += 1
CharIsUpperCase = 0
else:
detokenizer.append(engdict[inta])
detokenizer_idx += 1
if(CharIsUpperCase != 1):
detokenizer.append(" ")
detokenizer_idx += 1
debugw(engdict[inta])
# increment byte counter with step 2, we processed 2 bytes.
idx += 2
#elif((compressed[idx] & 128) and (compressed[idx+1] & 128)):
elif((compressed[idx] & 128) and (compressed[idx+1] & 128) and (not compressed[idx+2] & 128)):
# current index byte msb is at 1, and next byte mbs is at 1.
# it is one of the 4194304 next tokens in the dictionary.
debugw("rare word")
chunk = compressed[idx:idx+3]
# populate bitarray from the three bytes
c = bitarray(endian='little')
#c.frombytes(compressed[idx:idx+3])
c.frombytes(chunk)
debugw(c)
# remove second byte msb (shift down the bits above)
del c[15]
debugw(c)
# remove first byte msb (shift down the bits above)
del c[7]
debugw(c)
c.extend("0000000000")
# pad to 4 bytes (32 bit integer format) : 3 bytes + 10 bits
# because we previously removed two bits with del c[15] and del c[7]
debugw(c)
# convert bytes array to 32 bit unsigned integer
inta = (struct.unpack("<L", c.tobytes()))[0]
if (inta >= 524416):
# this is a ngram.
# remove offset to get into ngram dic code range.
inta -= 524416
debugw("this is an ngram. code:")
debugw(inta)
# process ngram through ngram dictionary
# replace ngram code with corresponding ngram string and add them to the tokenizer
ngram_string = ngram_dict_rev[inta]
debugw("ngram string:")
debugw(ngram_string)
subs = 0
#(ngram_string,subs) = re.subn(r'x',r'\\x',ngram_string)
(ngram_string,subs) = re.subn(r'x',r'',ngram_string)
debugw("ngram string:")
debugw(ngram_string)
ngram_bytes = bytes.fromhex(ngram_string)
subtokens = decompress_ngram_bytes(ngram_bytes)
#bytes = bytearray(ngram_string,encoding="ascii")
#subtokens.insert(0,"PREFIX")
#subtokens.append("SUFFIX")
#subtokens = nltk.word_tokenize(ngram_string)
# We know there shouldn't be any new lines in the subtokens.
# possessives, contractions or punctuation may occur.
# we need to add capitalization rules and spaces after punctuation rules.
# These should be catched by the detokenizer backward processor (detokenizer_idx -2)
# The problem is we append more than one token.
# So we should process rules for first subtoken insertion only.
# The rest should have inline processing (here)
if(CharIsUpperCase == 2):
detokenizer.append(subtokens[0].capitalize())
detokenizer_idx += 1
CharIsUpperCase = 0
else:
detokenizer.append(subtokens[0])
detokenizer_idx += 1
#if(CharIsUpperCase != 1):
# detokenizer.append(" ")
# detokenizer_idx += 1
ngram_processed_string = ngram_process_rules(subtokens[1:])
# We shoud take care that the backward detokenizer processor does not mingle
# with the the rest of the ngram string.
# Such a special token will be the only one to have whitespaces in it
# So we can detect it this way
detokenizer.append(ngram_processed_string)
detokenizer_idx += 1
else:
inta += (16384 + 128)
if(CharIsUpperCase == 2):
detokenizer.append(engdict[inta].capitalize())
detokenizer_idx += 1
CharIsUpperCase = 0
else:
detokenizer.append(engdict[inta])
detokenizer_idx += 1
if(CharIsUpperCase != 1):
detokenizer.append(" ")
detokenizer_idx += 1
debugw(engdict[inta])
# increment byte counter with step 3, we processed 3 bytes.
idx += 3
#elif((compressed[idx] == 255) and (compressed[idx+1] == 255) and (compressed[idx+2] == 255)):
elif((compressed[idx] & 128) and (compressed[idx+1] & 128) and (compressed[idx+2] & 128)):
#check if Huffmann first
chunk = compressed[idx:idx+3]
# populate bitarray from the three bytes
c = bitarray(endian='little')
#c.frombytes(compressed[idx:idx+3])
c.frombytes(chunk)
debugw(c)
# remove third byte msb (shift down the bits above)
del c[23]
debugw(c)
# remove second byte msb (shift down the bits above)
del c[15]
debugw(c)
# remove first byte msb (shift down the bits above)
del c[7]
debugw(c)
c.extend("00000000000")
# pad to 4 bytes (32 bit integer format) : 3 bytes + 8 bits + 3 bits
# because we previously removed three bits with del c[23], del c[15] and del c[7]
debugw(c)
# convert bytes array to 32 bit unsigned integer
inta = (struct.unpack("<L", c.tobytes()))[0]
inta -= 2097151
# if it is a Huffmann select tree code it will be 0 to 4 included
# if it is a session DIC it will be shifted in the negatives.
if (inta in range(0,5)):
# unknown word
# end check if Huffmann first
debugw("unknown word escape sequence detected, code: " + str(inta))
#unknown word escape sequence detected.
if(inta == 0):
char = compressed[idx+3]
stra = ""
idxchar = 0
while(char != 0):
debugw("char=")
debugw(char)
stra += chr(char)
debugw("printing string state=")
debugw(stra)
idxchar += 1
char = compressed[idx+3 + idxchar]
debugw("termination char detected=")
debugw(char)
else:
bstr = bytearray()
idxchar = 0
while(char != 0):
bstr.append(char)
idxchar += 1
char = compressed[idx+3 + idxchar]
debugw("huffmann : termination char detected=")
debugw(char)
stra = decode_unknown(bstr,inta)
#stra = codec.decode(bstr)
debugw("we append that unknown word in our session dic at idx: " + str(unknown_token_idx) + " since it may be recalled")
engdictrev[stra] = unknown_token_idx
engdict[unknown_token_idx] = stra
unknown_token_idx += 1
if(CharIsUpperCase == 2):
detokenizer.append(stra.capitalize())
detokenizer_idx += 1
CharIsUpperCase = 0
else:
detokenizer.append(stra)
detokenizer_idx += 1
if(CharIsUpperCase != 1):
detokenizer.append(" ")
detokenizer_idx += 1
else:
inta += 2097151
# it is a session DIC, shifting back to 0.
inta += (2097152 + 16384 + 128)
# it is a session DIC, shifting back session dic address space.
debugw("recalled word:")
try:
debugw(engdict[inta])
# print word
if(CharIsUpperCase == 2):
detokenizer.append(engdict[inta].capitalize())
detokenizer_idx += 1
CharIsUpperCase = 0
else:
detokenizer.append(engdict[inta])
detokenizer_idx += 1
if(CharIsUpperCase != 1):
detokenizer.append(" ")
detokenizer_idx += 1
except:
debugw("something went wrong, could not find word in session DIC")
for sessidx in range(2113664,unknown_token_idx):
debugw("session_index:" + str(sessidx))
debugw(engdict[sessidx])
debugw(engdictrev[engdict[sessidx]])
debugw("session_index:" + str(sessidx))
idx += 3 + idxchar
debugw(detokenizer)
if not(len(outfile)):
print(''.join(detokenizer))
else:
# write clear text to file if supplied in args
with open(outfile, 'w') as fh:
fh.write(''.join(detokenizer))